
KI Lab
KI-gestützte Anwendungen
Einleitung zu KI-gestützten Anwendungen
Der große Hype um Künstliche Intelligenz (KI) und insbesondere um Large Language Models (LLMs) begann mit der Veröffentlichung von OpenAI‘s Chat-GPT Ende 2022. Seitdem sind immense Summen an Kapital und menschlicher Intelligenz in dieses Feld geflossen. Das Ergebnis ist nicht nur eine wahre Flut an Forschungsergebnissen, die nur schwer zu überblicken ist, sondern auch die Entwicklung zahlreicher Software-Tools und Anwendungen, die darauf abzielen, diese neu entdeckten Möglichkeiten auszuschöpfen.
Inzwischen wollen (oder müssen) viele Unternehmen und Institutionen KI-gestützte Anwendungen einsetzen, um einen Mehrwert für ihre Stakeholder wie Kunden oder Mitarbeiter, und letztlich für ihre Kapitalgeber zu schaffen.
Entscheidungsprozesse und operative Workflows sind nur zwei Bereiche, die vom Einsatz von Machine-Learning-Tools enorm profitieren können. Ein prominentes Beispiel ist der Einsatz von Chatbots, die in der Lage sind, kompetent über spezifische Themen mit Mitarbeitern oder Kunden zu kommunizieren. Voraussetzung dafür ist, dass das zugrunde liegende Large Language Model und seine Komponenten auf die anwendungsspezifischen Daten trainiert sind.
Generative KI-Modelle wie ChatGPT werden primär auf Basis öffentlicher Daten trainiert. Sie berücksichtigen weder die internen – meist sensiblen – Daten eines Unternehmens noch die jeweiligen branchenspezifischen Gegebenheiten. Dadurch wäre der Einsatz solcher KI-Modelle in Unternehmen nicht nur ineffektiv, sondern würde zu fehlerhaften Ergebnissen führen und die Zuverlässigkeit der Anwendungen beeinträchtigen. Zudem müssten zur Nutzung eines kommerziellen LLMs wie dem von OpenAI dessen APIs verwendet werden. Das wiederum würde bedeuten, interne Daten mit dem ausgewählten Modell zu teilen, damit es das notwendige Wissen auf den konkreten Fall anwenden kann. Für die meisten Unternehmen ist diese Art der „Veröffentlichung“ interner Daten aus vielerlei Gründen keine Option, allen voran aus Datenschutz- und rechtlichen Gesichtspunkten.
Hier kommt Retrieval Augmented Generation (RAG) ins Spiel: RAG schließt die Lücke zwischen den allgemeinen Fähigkeiten generativer KI-Modelle und den spezifischen Bedürfnissen einzelner Institutionen. Es ermöglicht KI-Modellen den Zugriff auf große Mengen an Daten aus internen Dokumenten und Datenbanken in Echtzeit, um individualisierte, relevante, regelkonforme und vertrauenswürdige Informationen bereitzustellen.
Es ist wichtig zu verstehen, dass RAG keine Alternative, sondern eine Erweiterung bestehender generativer KI-Modelle ist. Zu diesem Zweck werden Frameworks wie Langchain verwendet, die ein LLM mit einer oder mehreren Komponenten verknüpfen, um eine Pipeline aufzubauen, die mit der Eingabeaufforderung (der Frage des Nutzers) beginnt und mit einer (hoffentlich) hilfreichen Antwort endet. Anstatt die Eingabeaufforderung direkt an das LLM zu senden, wird diese zunächst mit einer oder mehreren Komponenten der implementierten Pipeline verwendet. Die Aufgabe der Komponenten besteht darin, hilfreiche Informationen zu finden, um die spezifische Frage beantworten zu können. Diese Informationen werden der Eingabeaufforderung hinzugefügt und zusammen mit der ursprünglichen Frage an das LLM gesendet. Auf diese Weise kann das LLM dann eine Antwort mit einem hohen Maß an Genauigkeit und Relevanz generieren.
Die Basis-Komponente einer solchen Anwendung ist das LLM. Um die Sicherheit der Daten zu gewährleisten, sollte ein Open-Source-Modell verwendet werden, das lokal für die Inferenz verfügbar ist (in diesem Kontext also für die Beantwortung von Fragen). Ein weiteres wichtiges Element einer solchen KI-gestützten Pipeline ist ein Vektorspeicher – einfach formuliert eine Datenbank, in der die internen Daten der jeweiligen Nutzer in einem speziellen Format (große, mehrdimensionale Zahlenvektoren) kodiert und gespeichert werden. Vektorspeicher eignen sich besonders, um relevante Informationen schnell abzurufen. Die Nutzung eines durch einen Vektorspeicher unterstützten LLMs ist das, was in der Regel unter dem Begriff RAG verstanden wird.
Aber eine KI-gestützte Anwendung kann noch mehr. Wenn Sie ChatGPT schon einmal verwendet haben (und wer hat das nicht), dann wissen Sie sicherlich, dass ChatGPT Ihren Unterhaltungsverlauf kennt. Es merkt sich beispielsweise die Inhalte vorheriger Fragen und der jeweiligen Antworten und wird diese, sofern passend, berücksichtigen. Das Langchain-Framework bietet die Möglichkeit, ein Gedächtnis-Modul zu verwenden, das eine ähnliche Funktion erfüllt. Darüber hinaus kann man Komponenten hinzufügen, die eine Websuche durchführen, um aktuelle und / oder spezifische Informationen zu sammeln. Zudem können Sie Langchain nutzen, um sich mit einer speziellen Schnittstelle zu verbinden, beispielsweise um komplexe mathematische Formeln zu berechnen (zugegeben, das ist nicht der Standard-Anwendungsfall eines Chatbots). Ein weiteres Feature von Langchain sind Agenten, die es ermöglichen, unter anderem die Anwendung der ReAct-Logik (ursprünglich von Forschern der Princeton University und Google entwickelt) zu implementieren. Diese unterteilt komplexe Fragen in kleinere Schritte, die sie systematisch ausführt, um so eine zuverlässige Antwort zu erhalten. Außerdem könnte man sogar ein zweites LLM in eine Langchain-Pipeline, z.B. für eine Überprüfung bzw. weiteren Verifizierung, implementieren.
Zusammenfassung: Wie können Institutionen von RAG profitieren?
Die individuelle Anpassung von KI-gestützten Workflows mit Hilfe eines lokal verfügbaren Open-Source-LLMs und einer RAG-Komponente bietet zahlreiche Vorteile, darunter:
- Verbesserte Prozesse und Ergebnisse: Interne Informationen zur Erstellung von präzisen und relevanten Antworten zu nutzen und diese Mitarbeitern und / oder Kunden zugänglich zu machen, ermöglicht es Unternehmen, Entscheidungsprozesse zu optimieren und ihre operative Effizienz zu steigern.
- Erhöhte Datensicherheit: RAG-Modelle können in interne Datensysteme von Unternehmen integriert werden. Dadurch wird sichergestellt, dass sensible Informationen in einem kontrollierten Umfeld geschützt bleiben und sich das Risiko verringert, dass diese an die Öffentlichkeit gelangen.
- Compliance und Integrität: Durch den Verbleib vertraulicher Daten im Unternehmen können Vorschriften leichter eingehalten und die Integrität der Daten besser geschützt werden.
hessian.AI entwickelt KI-gestützte Anwendungen
In hessian.AI’s AI Lab entwickeln wir Prototypen von KI-gestützten Anwendungen. Einer dieser Prototypen besteht aus einem Frontend und einem Backend. Das Frontend dient zur Interaktion. Nutzer können verschiedene Parameter der KI-gestützten Anwendung auswählen. So können sie beispielsweise entscheiden, welches lokal verfügbare LLM verwendet werden soll (zwei der derzeit stärksten Open-Source-LLMs: Meta’s Llama-3.1-70b und Google’s gemma-2-27b). Zudem können sie sich entweder für eine weniger aufwendige Lösung entscheiden, nämlich ein Dokument in Echtzeit in einen In-Memory-Vektorspeicher (z.B. FAISS) hochladen, oder für ein eher kommerzielles Szenario, indem sie einen echten Vektorspeicher (z.B. Milvus oder Postgres pgvector) verwenden. In diesem Fall müssen die Daten, die später abgerufen werden sollen, im Voraus in den Vektorspeicher hochgeladen werden. Zusätzlich können sie zwischen verschiedenen Methoden der Zerlegung bezüglich der Token-Generierung sowie zwischen verschiedenen Modellen zur Einbettung wählen, die während des Hochladens und Kodierens verwendet werden sollen. Sobald die Nutzer ihre Auswahl getroffen haben, können sie Fragen stellen und erhalten Antworten, die den jeweiligen Kontext (also die konkreten Daten, die zur Beantwortung der Frage abgerufen wurden) berücksichtigen.
Aus architektonischer Sicht verwendet die Anwendung zwei Docker-Container: einen für das Frontend und einen für das Backend. Der ausgewählte Vektorspeicher befindet sich auf einer virtuellen Maschine (VM), es könnte hierfür aber auch ebenfalls ein weiterer Docker-Container genutzt werden. Die Inferenz des LLM erfolgt auf einem Server mit mehreren Nvidia A-100 GPUs.
Hauptverantwortlich für dieses Projekt ist Perpetue Kuete Tiayo, Softwareentwicklerin im AI Lab. Besonderer Dank geht an Patrick Blauth, Kajol Raju und Lev Dadashev (Softwareentwickler/KI-Experten im AI Lab, dem AI Service Center und dem AI Innovation Lab), insbesondere für das Aufsetzen und Einrichten der Vektorspeicher und die Implementierung des relevanten Codes. Das Team wird zukünftig weiter an der Optimierung des Prompt-Engineerings arbeiten.
hessian.AI bietet Beratung und Unterstützung bei der Entwicklung und Implementierung von KI-Lösungen an. Für Institutionen und Unternehmen, die an der Implementierung einer KI-gestützten Anwendung interessiert sind, erarbeiten wir maßgeschneiderte Lösungen. Eine solche individuell angepasste Anwendung unterscheidet sich in der Regel etwas von dem oben beschriebenen Prototyp: Normalerweise wird nur einer der verfügbaren Vektorspeicher sowie nur ein Open-Source-LLM implementiert. Das Frontend wird den Anforderungen des spezifischen Anwendungsfalls entsprechend gestaltet und programmiert. Ähnlich wie beim Prototyp werden in der Regel mehrere Docker-Container und/oder virtuelle Maschinen verwendet. Für Anwendungen mit vielen Nutzern und einem potenziell hohem Workload kann es zudem sinnvoll sein, ein Kubernetes-Cluster für die Implementierung zu nutzen. Kubernetes ist das ideale Instrument für das Management und insbesondere für die Skalierung der eingesetzten Docker-Container. Wir arbeiten gerne mit Ihnen zusammen, um eine Anwendung zu entwickeln, die auf die individuellen Bedürfnisse Ihres Unternehmens zugeschnitten ist.
Autor: Patrick Blauth, Software-Entwickler/AI Systems Research Engineer (AI Lab)
Sie möchten mehr erfahren?
Wenn Sie mehr über unsere RAG-API-Architektur erfahren oder besprechen möchten, wie wir Ihnen bei der Bereitstellung helfen können, kontaktieren Sie gerne unser AI Lab () oder unser Innovation Lab ().
RAG-API: Architektur und Bereitstellung
Hessian.AI’s AI Lab hat eine Retrieval-Augmented Generation (RAG)-API entwickelt und bereitgestellt, die über ein modernes Frontend, ein robustes Backend und eine sichere Abfrageweiterleitung mit Nginx verfügt. Diese Architektur vereinfacht nicht nur den Bereitstellungsprozess, sondern verbessert auch die Leistung, Sicherheit und Skalierbarkeit.
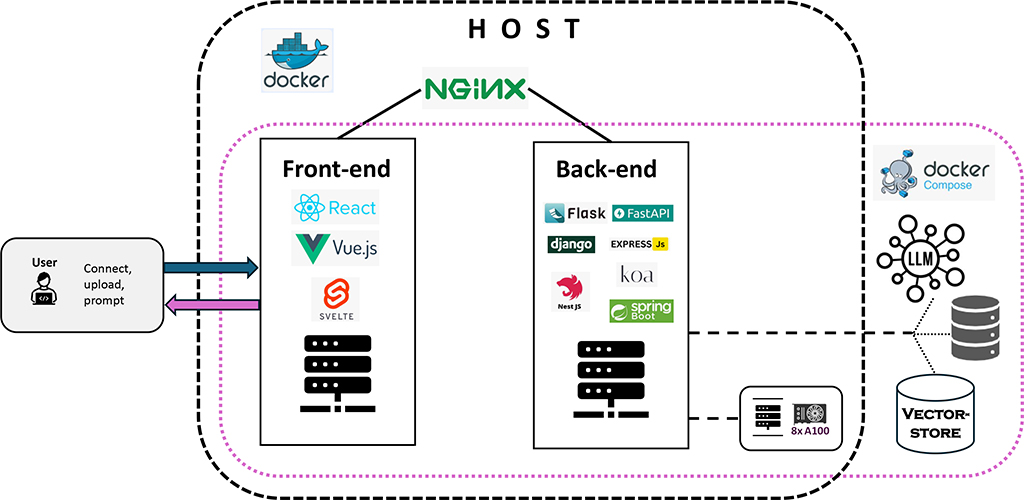
Übersicht über die Architektur
Frontend
- Mit ReAct und Vite für eine schnelle und reaktionsfähige Benutzeroberfläche entwickelt.
- Einfaches Formular zur Eingabe von Anfragen und Anzeige von Antworten.
Backend
- Mit FastAPI erstellt. Das Backend übernimmt die Abfrageverarbeitung, das Abrufen, die Erweiterung und die Generierung.
- Nutzung von GPUs für die Modellinferenz, um eine hohe Leistung zu erzielen. Verfügbar innerhalb des Docker-Containers mittels des NVIDIA Container Toolkits.
- Sprachmodelle und Daten werden auf einem externen Dateisystem gespeichert, das in den Backend-Docker-Container eingebunden ist, um Datenpersistenz, einfache Updates und Skalierbarkeit zu gewährleisten.
- Verwendung von Hugging Face Transformers für die Modellinferenz und FAISS für effiziente Ähnlichkeitssuche.
Nginx
- Zur Bereitstellung statischer Frontend-Dateien und als Reverse Proxy für die Backend-API.
- Übernimmt die SSL-Terminierung, um die Kommunikation zwischen Clients und dem Server sicherzustellen.
Docker
- Containerisierung von Frontend und Backend zur Sicherstellung von konsistenten Umgebungen von der Entwicklung über die Testphase bis hin zur Produktion.
- Einbindung eines externen Dateisystems in den Backend-Container, um Sprachmodelle und Daten zu hosten.
Warum dieses Setup?
- Trennung: Diese Architektur trennt Frontend und Backend sauber voneinander, was die Entwicklung und Wartung erleichtert.
- Skalierbarkeit: Docker-Container erleichtern das unabhängige Skalieren der verschiedenen Teile der Anwendung.
- Sicherheit: Nginx bietet SSL-Terminierung und schützt die Daten während der Übertragung.
- Leistung: Der Einsatz von GPUs innerhalb der Docker-Container beschleunigt die Modellinferenz erheblich, dank NVIDIA Container Toolkit.
- Beständigkeit: Die Einbindung eines externen Dateisystems in den Backend-Container stellt sicher, dass große Modelle und Daten nicht Teil des Container-Images sind. Dies vereinfacht die Durchführung von Updates und ermöglicht eine bessere Nutzung von Speicherkapazitäten.
Grundlegende Schritte zur Umsetzung
Frontend containerisieren
- Vite zum Erstellen der React-App nutzen.
- Statische Dateien mit Nginx bereitstellen.
Backend containerisieren
- Docker File für das FastAPI-Backend erstellen.
- NVIDIA Container Toolkits verwenden, um GPU-Ressourcen innerhalb des Containers zu nutzen.
- Ein externes Dateisystem mit App / Modell im Container verknüpfen, um auf LLM und Daten zuzugreifen.
Nginx-Konfiguration
- Nginx konfigurieren, um statische Frontend-Dateien bereitzustellen und API-Anfragen an das Backend weiterzuleiten.
Bereitstellung
- Docker Compose zur Verwaltung von Multi-Container-Anwendungen nutzen.
- Sicherstellen, dass das externe Dateisystem zugänglich und korrekt eingebunden ist.
Autor: Perpetue Kuete Tiayo, Software-Entwickler/AI-Forscher (AI Lab)