
AI Lab
AI-powered Applications
Introduction to AI-powered Applications
The current great hype about Artificial Intelligence (AI), and more specifically Large Language Models (LLMs), started with the upcoming of OpenAI’s Chat-GPT at the end of the year 2022. Since then, exceptional amounts of capital and human intellectual resources have poured into this field. The result is a surge in research that is difficult to keep track of as well as the development of numerous software tools and applications designed to make use of, and create added value for, this newly discovered field of opportunities.
Today, many companies and other institutions want to, or are even forced to, add AI-supported tools into their arsenal to create value for their stakeholders, e.g. customers or employees, and ultimately, for their capital holders.
From a top-level view, decision-making processes and operational workflows are two important examples where the use of Machine Learning tools has the potential to create huge benefits. One of the most prominent concrete examples is the use of chatbots which are able to communicate with employees or customers about domain-specific topics in a very knowledgeable manner. A prerequisite for this is that the underlying Large Language model and its components are trained to know the use-case specific data.
Generative AI models like ChatGPT are primarily trained on public data. They consider neither the company’s internal – and in most cases sensitive – data, nor the industry-specific circumstances. As a result, utilizing such AI models would not only lack effectiveness but also lead to flawed results, compromising their reliability. Furthermore, using one of the commercial LLM offerings like the one from OpenAI would result in using their APIs and therefore sharing internal data with the selected commercial model, so it would be able to adjust to the necessary knowledge. For many institutions, “giving away” internal data is not an option for several reasons, foremost data security and legal issues.
This is where Retrieval Augmented Generation (RAG) comes in: RAG bridges the gap between the general capabilities of generative AI models with the specific needs of an individual institution. It enables AI models to access large amounts of internal documents and databases in real-time to provide individualized, relevant, compliant, and trustworthy information.
In this context, it is important to understand that RAG is not an alternative but an extension of existing generative AI models. For this purpose, frameworks like Langchain are used to connect an LLM with one or more components to build a pipeline which starts with the prompt (the user’s question) and ends with a (hopefully) helpful answer. But instead of sending the prompt directly to the LLM, it is first used with one or more components of the implemented pipeline. The task of these components is to gather information that is helpful to answer the specific question. This retrieved information is then added to the prompt, thereby sending to the LLM not only the initial question but also valuable information in this regard. This enables the LLM to generate an answer with a high degree of accuracy and relevance.
The base component of such an application is the LLM. To ensure the security of the data, this should be an open-source model which is locally available for inference (in this context meaning for question-answering). Another important cornerstone of such an AI-powered pipeline is a vectorstore which, in simple terms, is a database where the internal data of the respective user will be encoded and saved in a special format (large-sized multi-dimensional number vectors). Given an input, these vectorstores are especially suitable and fast for retrieving relevant information. The use of an LLM supported by a vectorstore is what is mainly understood by the term RAG.
But an AI-powered application can do even more. If you have used ChatGPT before (and who hasn’t), then you probably know that ChatGPT is aware of your dialog, e.g. it knows the content of your previous questions and the respective answers and will take it into account, if appropriate. In the Langchain framework, one has the possibility to use a memory component, which basically serves a similar function. Furthermore, one can use components to execute a web search for gathering very recent and/or specific information. Also, it can be used to connect to an API of your choice to e.g. calculate complex mathematical expressions (admittedly not the standard use case of a chatbot). Another feature Langchain has to offer are agents, which enable you, among other things, to implement the application of ReAct logic (originally developed by researchers from Princeton university and Google), which tries to break down complex questions into more manageable steps and execute them in a systematic manner to ultimately come up with a reliable answer. Finally, one could even implement a second LLM into a Langchain pipeline, using it e.g. for crosschecking purposes.
To summarize: How can institutions benefit from RAG?
Customizing workflows using AI-powered applications including a locally available open-source LLM and a RAG component as main building blocks provides numerous benefits, including:
- Enhancing business processes and results: By using proprietary information for precise and contextually relevant responses and offering these capabilities to a wide range of employees and/or clients, companies can improve their decision-making and operational efficiency.
- Enhanced data security: RAG models can integrate with companies’ internal data, ensuring that sensitive information remains secure within controlled environments and reducing exposure risks.
- Compliance and integrity: Keeping proprietary data in-house helps companies comply with regulations and maintain data integrity.
hessian.AI is building AI-powered applications
At the AI Lab of hessian.AI, we are building prototypes of AI-powered applications. One large example of these prototypes consists of a frontend and a backend. The frontend is used as the tool for interaction. Here, users can select various parameters of the AI-powered application. For example, they can choose which locally available LLM to use (among others, the two strongest open-source LLM’s currently available: Meta’s Llama-3.1-70b and Google’s gemma-2-27b). Furthermore, they can either opt for a light-weight solution by uploading a document in real-time into an in-memory vectorstore (e.g. FAISS) or for a more commercial scenario-like case by using a true vectorstore (e.g. Milvus or Postgres pgvector). In this case, the data to be retrieved later, has to be uploaded into the vectorstore in advance. Additionally, users can choose between different token-generating splitting methods as well as between different embedding models used during the uploading and encoding process. Having made their choices, users can then ask questions and receive answers that also include the context (the concrete data that has been retrieved to support the question).
From an architectural perspective, the application uses two docker containers: one for the frontend, and one for the backend. Furthermore, the selected vectorstore lies on virtual machine, but this could also be dockerized. The inference of the LLM is done on a server with several Nvidia A-100 GPUs. Please see the last section for more information about the technical details.
This project is mainly the product of one of AI Lab’s Software Developers: Perpetue Kuete Tiayo. Honorable mentions, especially in the context of setting up the vectorstores and implementing the relevant code in this context, go to Patrick Blauth, Kajol Raju and Lev Dadashev (Software Developers/AI experts from the AI Lab, the AI Service Center, and the Innovation Lab). Going forward, the team is going to work on further optimizing the prompt engineering.
Hessian.AI provides consulting and supporting services in the context of AI solutions. For institutions and companies interested in implementing an AI-powered application, hessian.AI offers to develop tailor-made solutions. The setup of such a customized application would be slightly different from the prototype described above: Typically, only one of the available vectorstores and also only one open-source LLM are implemented. The frontend would be designed and programmed to match the needs of the specific use case. Similar to the prototype, the deployment would usually be executed using several docker containers and/or virtual machines. For implementations with many users and potentially heavy workloads, it also could make sense to implement the application through a Kubernetes cluster, which is the ideal instrument for managing and especially scaling the needed docker containers in accordance with the actual usage. We are happy to work with you to build an application that matches your company’s needs.
Author: Patrick Blauth, Software Developer/AI Systems Research Engineer (AI Lab)
Interested in learning more?
If you would like to find out more about our RAG API architecture or discuss how we can assist you with the deployment process, please feel free to contact our AI Lab () or our Innovation Lab ().
RAG API architecture and deployment
The AI Lab at hessian.AI has built and deployed a Retrieval-Augmented Generation (RAG) API with a modern frontend, robust backend, and secure query forwarding using Nginx. The architecture not only simplifies the deployment process but also enhances the performance, security, and scalability.
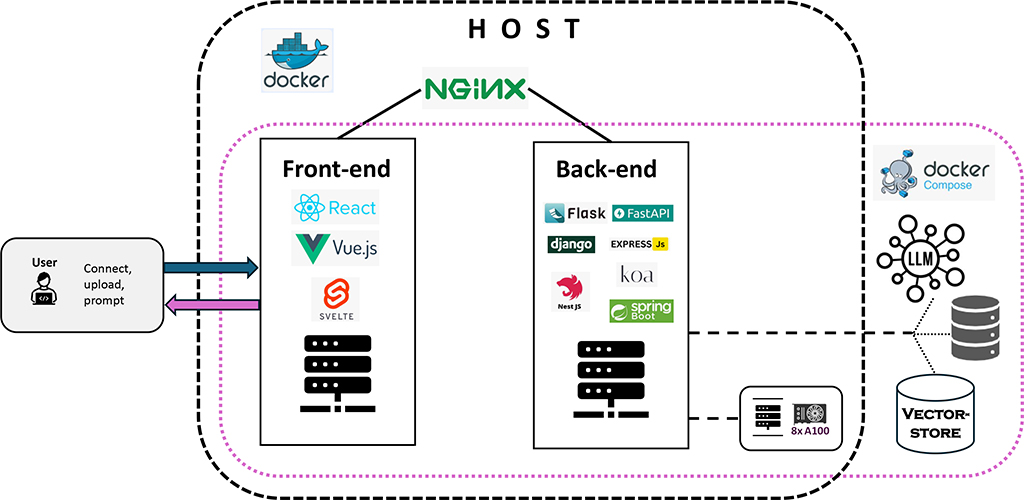
Architecture overview
Frontend
- Developed using React with Vite for a fast and responsive user interface.
- Simple form to input queries and display responses.
Backend
- Built with FastAPI, the backend handles query processing, retrieval, augmentation, and generation.
- Utilizes GPUs for model inference to achieve high performance, made available inside the Docker container using the NVIDIA Container Toolkit.
- Language models and data are stored on an external file system, which is mounted to the backend Docker container. This ensures data persistence, easy updates, and scalability.
- Utilized Hugging Face Transformers for model inference and FAISS for efficient similarity search.
Nginx
- Serves static frontend files and acts as a reverse proxy for the backend API.
- Handles SSL termination to secure communications between clients and the server.
Docker
- Both the frontend and backend are containerized, ensuring consistent environments across development, testing, and production.
- External file system mounted to the backend container to host the language models and data.
Why this setup?
- Separation of concerns: The architecture cleanly separates the frontend and backend, making development and maintenance more manageable.
- Scalability: Docker containers make it easy to scale different parts of the application independently.
- Security: Nginx provides SSL termination, protecting data in transit.
- Performance: Leveraging GPUs within Docker containers significantly speeds up model inference, thanks to the NVIDIA Container Toolkit.
- Persistence: Mounting an external file system to the backend container ensures that large models and data are not part of the container image, allowing for more straightforward updates and better use of storage resources.
High-level steps to achieve his
Dockerize the frontend
- Use Vite for building the React app.
- Serve static files from Nginx.
Dockerize the backend
- Create a Dockerfile for the FastAPI backend.
- Use the NVIDIA Container Toolkit to leverage GPU resources inside the container.
- Mount an external file system to /app/models inside the container to access LLM and data.
Nginx configuration
- Configure Nginx to serve frontend static files and reverse proxy API requests to the backend.
Deploy
- Use Docker Compose to manage multi-container applications.
- Ensure the external file system is accessible and mounted correctly.
Author: Perpetue Kuete Tiayo, Software Developer/AI Researcher (AI Lab)