Research & Application – 3rd wave of AI
hessian.AISC’s research activities aim to build a bridge from AI research to application and strengthen the “AI made in Germany” brand. We focus on translating the results of our basic research into services and applications, which in turn raise new questions for research.
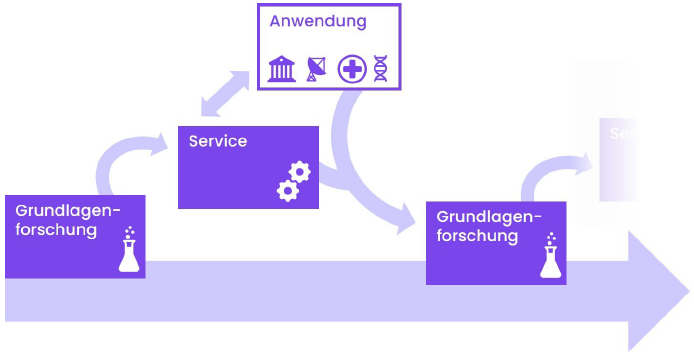
The service center works closely with hessian.AI researchers, the public sector, and Hessian companies. We aim to lower the barriers to the application of artificial intelligence by providing demonstrators and directly applicable models.
We support users in applying our research results through a variety of educational training programs and services.
Main research areas
As part of the 3rd wave of AI, the hessian.AISC focuses on
- large generalizable models
- transparency & explainability
- contextual adaptation
- utilization of specific (network) structures
to develop and provide robust, secure, and sustainable AI systems for a broad range of users.
Data sets, models, and demonstrators
The following models have been developed, trained, and made available as demonstrators by hessian.AI as part of the AI Service Center’s research to date:
V-LoL Datensatz – Visual Logical Learning
Despite the successes of recent developments in visual AI, different shortcomings still exist; from missing exact logical reasoning, to abstract generalization abilities, to understanding complex and noisy scenes.
read more
Unfortunately, existing benchmarks, were not designed to capture more than a few of these aspects. Whereas deep learning datasets focus on visually complex data but simple visual reasoning tasks, inductive logic datasets involve complex logical learning tasks, however, lack the visual component. To address this, we propose the visual logical learning dataset, V-LoL, that seamlessly combines visual and logical challenges. Notably, we introduce the first instantiation of V-LoL, V-LoL-Trains, — a visual rendition of a classic benchmark in symbolic AI, the Michalski train problem. By incorporating intricate visual scenes and flexible logical reasoning tasks within a versatile framework, V-LoL-Trains provides a platform for investigating a wide range of visual logical learning challenges. We evaluate a variety of AI systems including traditional symbolic AI, neural AI, as well as neuro-symbolic AI. Our evaluations demonstrate that even state-of-the-art AI faces difficulties in dealing with visual logical learning challenges, highlighting unique advantages and limitations specific to each methodology. Overall, V-LoL opens up new avenues for understanding and enhancing current abilities in visual logical learning for AI systems.
Dataset: https://huggingface.co/datasets/AIML-TUDA/v-lol-trains
LeoLM – First open German Foundation Language Model
LeoLM (Linguistically Enhanced Open Language Model) is a high-quality bilingual (German/English) language model. It is based on the LLama-2 architecture and was trained and fine-tuned with an extensive, high-quality German text corpus.
read more
LeoLM was pre-trained with two billion primary English language tokens and 65 billion specifically filtered and deduplicated tokens from web texts of the OSCAR-2301 corpus. The model was fine-tuned using six German or German-English language datasets.
The quality of the model was improved by using linear RoPE scaling and Flash Attention 2 to enhance training efficiency and double the context length to 8k tokens.
Below you find a detailed description of the model, the associated repositories and corresponding chat demonstrators.
This project was developed in cooperation with the non-profit organization LAION. We are grateful for the excellent partnership and support.
Detailed description: LeoLM: Igniting German-Language LLM Research | LAION
Demonstrator 7b: LeoLM Chat-Demonstrator
Repository 7b: LeoLM/leo-hessianai-7b · Hugging Face
Demonstrator 13b: LeoLM 13b Chat – a Hugging Face Space by LeoLM
Repository 13b: LeoLM/leo-hessianai-13b · Hugging Face
StripedHyena-7B – Long context LLM
The StripedHyena7B model is based on the hybrid Hyena Architecture. It is made up of multi-headed, grouped queries and gated convolutions arranged in Hyena blocks and differs from conventional decoder-only Transformers.
read more
This architecture enables
- cost-effective memory decoding in Hyena blocks by representing convolutions as state space models (modal or canonical form) or as truncated filters.
- low latency, faster decoding, and higher throughput than Transformers.
- improved training and inference-optimal scaling laws compared to optimized Transformer architectures such as Llama-2.
- by training on sequences of up to 32k, longer prompts can also be processed.
This makes StripedHyena 7B the first alternative model that can compete with the best open-source Transformers in short and long context evaluations.
The project as developed in cooperation between hessian.AISC and Together Computer Inc. We are grateful for the excellent partnership and support.
Detailed description: Paving the way to efficient architectures: StripedHyena-7B, open source models offering a glimpse into a world beyond Transformers
Repository 13b Foundation model: togethercomputer/StripedHyena-Hessian-7B · Hugging Face
Repository 13b Chat model: togethercomputer/StripedHyena-Nous-7B · Hugging Face
Demonstrator: http://stripedhyena.hessian.ai/
Occiglot-7B-EU5 – Multilingual European LLM
Occiglot-7B-EU5 is a generative language model with seven billion parameters that supports the five most important EU languages: English, Spanish, French, German, and Italian. It is based on Mistral-7B-v0.1. It was trained on 293 billion tokens of additional multilingual and coded data with a block size of 8.192 tokens per sample.
read more
Occiglot-7B-EU5 is a general basic model that has neither been tuned for commands nor optimized for chats or other applications.
The model was trained in cooperation between the German Research Center for Artificial Intelligence (DFKI) and hessian.AISC.
Repository: occiglot/occiglot-7b-eu5 · Hugging Face
Demonstrator: http://occiglot.hessian.ai/
LLavaGuard –Safeguards for Vision Dataset Curation and Safety Assessment
We introduce LlavaGuard, a family of VLM-based safeguard models, offering a versatile framework for evaluating the safety compliance of visual content. Specifically, we designed LlavaGuard for dataset annotation and generative model safeguarding.
read more
To this end, we collected and annotated a high-quality visual dataset incorporating a broad safety taxonomy, which we use to tune VLMs on context-aware safety risks. As a key innovation, LlavaGuard’s responses contain comprehensive information, including a safety rating, the violated safety categories, and an in-depth rationale. Further, our introduced customizable taxonomy categories enable the context-specific alignment of LlavaGuard to various scenarios. Our experiments highlight the capabilities of LlavaGuard in complex and real-world applications. We provide checkpoints ranging from 7B to 34B parameters demonstrating state-of-the-art performance, with even the smallest models outperforming baselines like GPT-4. We make our dataset and model weights publicly available and invite further research to address the diverse needs of communities and contexts.
Modell 7b: https://huggingface.co/AIML-TUDA/LlavaGuard-7B
Modell 13b: https://huggingface.co/AIML-TUDA/LlavaGuard-13B
Modell 34b: https://huggingface.co/AIML-TUDA/LlavaGuard-34B
Demonstrator: https://huggingface.co/spaces/AIML-TUDA/LlavaGuard
German LLama3
The Llama3-German-8B model is a specialized adaptation of Meta’s Llama3, tailored for the German language. Trained on 65 billion high-quality German-language tokens, it excels in processing and understanding complex German texts.
read more
One key feature is its ability to handle long contexts, managing up to 32,000 tokens, which makes it highly effective for tasks involving the analysis of extended text passages.
The model has also been fine-tuned using datasets for instruction-based tasks, allowing it to provide precise answers to questions and understand more complex instructions. These capabilities are particularly useful for developing natural language processing applications in German-speaking regions. By focusing on the German language, the model reduces reliance on international technologies and supports research and development in the field of AI within German-speaking areas.
Modell: https://huggingface.co/DiscoResearch/Llama3-German-8B-32k
DiscoLM
The DiscoLM model by DiscoResearch is an advanced AI language model specifically tailored to the German language and its unique characteristics.
read more
Based on the Mistral model, DiscoLM was trained on billions of German-language data points, excelling in natural language understanding and precise text generation. It is designed to perform exceptionally well in German-speaking applications, such as natural language processing, text generation, and instruction-based tasks.
One of DiscoLM’s key advantages is its ability to meet the specific demands of the German language, offering significant improvements over many common English-based models. This enhances Germany’s AI sovereignty by reducing reliance on international, English-focused models and supporting the development of locally adapted AI solutions. Additionally, DiscoLM performs exceptionally well in fine-tuning for specific tasks like question answering and information retrieval, making it a valuable tool for businesses and research.
Through close collaboration with partners such as LAION and Hessian.AI, the model has been optimized to cater to the needs of the German-speaking community.
Current research activities
Current research projects of our doctoral students:
Intelligent data documentation and data cleansing [Lukas Helff]
Quality and size of training data are crucial for the successful development of modern AI applications. Data documentation and data cleansing play a central role, especially with the emergence of popular models like GPT-4, which are gaining importance in various fields. With the increasing autonomy of these AI systems, their social, scientific, and industrial impacts grow. Therefore, high-quality data is needed to avoid biases and stereotypes.
read more
However, manually annotating large datasets is not only prone to errors but also labor- and resource-intensive. Intelligent data documentation and data cleansing present key solutions to these challenges, aiming to optimize the preparation of high-quality data for AI applications.
In this context, the research focuses on the potential of machines to assist in documenting potentially inappropriate content by leveraging the knowledge stored in Transformer models. This could significantly reduce the human effort in data preparation.
We aim to develop intelligent data documentation and data cleansing that can be offered as a service to detect inappropriate content. Planned steps include training documentation models for images, expanding to text and tabular data, as well as automatically documenting mixed data. By generative and axiomatic alignment of documentation models and offering these as a service, practicality and marketability are ensured.
The results of this research project will be utilized by the AI Service Center as modules for data documentation, cleansing, and quality assurance.
Adaptation of large (vision) language models [Christopher Tauchmann]
The project “Adapting Large (Vision-) Language Models” focuses on adjusting large (vision-) language models to downstream tasks, and more general demands. To this end, we pursue several lines of research:
read more
Particular interest lies in using modular and parameter-efficient transfer learning methods. Such methods update only a fraction of a model’s parameters, add a small number of trainable parameters, or reuse other existing parameters. Other methods learn smaller models from larger ones or combine multiple modules.
Using different prompting techniques, we analyze and leverage in-context learning skills, where a model learns from the examples provided in the input prompt. This proves to be highly promising to adapt models on-the-fly, or—in the case of instruction-tuning—as a related learning technique to prime models towards certain requirements. Retrieval augmented generation enhances a model’s capabilities by using external knowledge.
We also deep-dive into model architectures: interpreting and editing model-internal representations, e.g., by tracing the information flow or analyzing individual model components. One such approach views the model’s modules as part of a stream that can be mapped back to the input at any point, where editing the stream at specific locations leads to measurable results.
We investigate which tasks benefit from different approaches. As today’s very large models perform very well on a large number of tasks—language-only models perform on most, if not all, traditional NLP tasks—we are particularly interested in their reasoning skills.
AI hardware for Data Processing [Nils Boeschen]
This research project investigates how AI hardware (e.g., Graphical Processing Units – GPUs) can accelerate data processing tasks for hard disk- and network-based data access.
read more
GPUs are known to be powerful compute units for many data- and processing-intensive workloads and often outperform CPUs on these tasks by multiple orders of magnitude. We investigate how to exploit these computational benefits for data processing on modern storage and fast networks. Our research results show that with techniques like heavy-weight decompression and pruning, GPUs can reach a significant increase in data loading and processing bandwidth that is unattainable for CPU systems today.
Scalable Data Processing using Tensor Runtimes [Nils Boeschen]
This research project evaluates how current tensor processing runtimes, such as PyTorch and Tensorflow, can be used as platforms for distributed query processing. These runtimes are interesting as general purpose query processing executors, as they support a variety of hardware types (CPUs, GPUs, TPUs, etc.), data formats, and data operations “out-of-the-box”.
read more
It has been shown that for single node setups, SQL queries can be transformed into a series of operations compatible with tensor runtimes, and that the performance of this type of execution is comparatively high. However, it is yet unclear if these advantages also scale in a networked setting.
Since distributed query processing requires efficient key-based network shuffles, overlap of network and compute operations, as well as skew handling, the transformation is non-trivial. In this line of research, we investigate how distributed queries can be transformed to be efficiently executable over tensor processing runtimes with the same benefits.
Code Transformers [Mert Tiftikci]
The research project “Code Transformers” focuses on understanding and improving generative AI models for code. Advanced code models created can help developers in their tasks, acting as their colleagues in terms of pair programming. It is not enough to generate compilable and easily readable code. Instead, the code models should also solve the problems raised by the developer while complying with industry standards, even for newly introduced projects and libraries. This can be achieved when AI models can understand the code syntactically as well as semantically.
read more
Current high-performing models have black-box structures that learn from huge piles curated by collecting code in the “wild.” Such datasets contain vulnerable codes or even malware. In addition, many of those models learn from these datasets by predicting the completion of a given code sequentially, disregarding the rich structure it contains.
This project aims to reach efficient code models by investigating the depth of their understanding as well as their limitations first. This will be followed by designing customizable and modular structures that can utilize various techniques, such as multimodal training or neuro-symbolic learning. Such models can utilize rich meta-data attached to the code, adapt according to user preferences, and are more trustworthy, as they can provide explanations to their generations.
Use of structure and multimodality in transformer models [Falko Helm]
The Hessian.AI funded research project “Structure and Multimodality for Transformer Networks” is about dealing with documents such as PDF and XML files (e.g. MS Word).
In the past, language understanding systems discarded everything but the plain text when processing a document. The goal of this project is to work directly with raw documents without any preprocessing. This includes considering the different modalities (text, images, tables, charts) as well as their interplay in the form of layout and explicit links.
read more
To provide some background, let’s dissect the project title word by word. “Multimodality” means that there are non-text elements present in the document. For example, these can be images, tables or charts. The modalities video and audio are not considered because they are quite rare in business documents. Importantly, multimodality means that the modalities are interleaved and their interplay is complex, i.e. we will go beyond simple pairs of image and corresponding text caption.
The term “structure” refers to everything which goes beyond text as a plain sequence of characters. Structure can manifest itself via linebreaks in a poem, chapters in a book or columns in a newspaper. Further, “structure” also describes the relations between text and non-text elements of a document. This can be implicit by the spatial arrangement or explicit via references to tables and charts.
A “Transformer” is a special kind of Neural Network (i.e. a model that can learn from data) and can be used for analysis and prediction. In the language domain, most recent breakthroughs (i.e. ChatGPT) were mainly due to this architecture. Currently, the vanilla Transformer pushes hardware to the limit as its key component, the so-called self-attention, scales poorly with sequence length. Thus, we also want to look into recent attention-free models, e.g. state space models such as Mamba.
The field of AI is moving very fast though, so these plans are preliminary and can become obsolete tomorrow.
Support for non-standard DNNs [Tim Noack]
Despite their widespread use, traditional neural networks struggle with modeling uncertainties and require extensive training data. These limitations can be problematic, for example, when their predictions need to be understandable. Probabilistic Circuits (PCs) offer a compelling alternative to neural networks. Sum-Product Networks (SPNs), a key member of the PC family, stand out due to their efficient inference capability, the ability to be trained with relatively few data and hyperparameters, and their intrinsic capacity to model the uncertainty of their predictions. However, deploying SPNs on computational platforms like CPUs, GPUs and FPGAs presents some challenges. These networks do not align well with massively parallel architectures due to their sparse connections and convergence to a single output node.
read more
This project tackles these issues by developing an MLIR-based SPNC compiler. It aims to bridge the gap between advancing hardware architectures and the accessibility of these powerful models to AI practitioners without any hardware expertise. The SPNC compiler is designed to seamlessly integrate into existing machine learning frameworks, automatically mapping models to the target hardware. This integration maximizes hardware utility and minimizes the learning curve for AI researchers and developers. By enabling efficient computation of SPNs on specialized hardware, such as FPGAs and IPUs, this project opens up new avenues for AI applications.
Current application projects
ETH Text-to-Music
We are collaborating with ETH Zurich to develop a text-to-music model with 1 to 3 billion parameters. This model is designed to generate music pieces based on text prompts, tempo, and keywords.
We are using a high-quality partial dataset from the FMA music dataset and the Jamendo royalty-free music dataset to train the model.
The trained model and the training data will be released under an open-source license.
Cooperation partner: Luca Lanzendörfer, Distributed Computing Group, ETH Zurich
Haris’ MorphPiece Tokenization
In cooperation with Haris Jabbar, we are validating and evaluating a novel tokenization scheme for the English language that integrates morph-based segmentation with byte pair encoding to improve NLP models.
We aim to test a more linguistically-focused tokenization mechanism that enhances the model’s understanding of linguistic nuances and, consequently, improves the model’s performance. At the same time, it should support a more efficient handling of languages with rich morphology (compared to methods that solely rely on statistical analyses).